
Teil 2 der Blog-Serie

Integration von KI ins Requirements Engineering: Ein Praxisbeispiel mit ChatGPT
Herzlich willkommen zum zweiten Teil unserer Blogserie über die Integration von Künstlicher Intelligenz (KI) ins Requirements Engineering! Im ersten Teil unserer Serie lag der Fokus auf der Identifikation relevanter Abschnitte der Datenschutz-Grundverordnung (DSGVO) zur Ableitung von Systemanforderungen. Dabei haben wir mithilfe von KI, genauer gesagt ChatGPT 4, den Einsatz im Kontext der Entwicklung eines Multimediasystems für PKWs untersucht. Jetzt gehen wir einen weiteren Schritt, indem wir die Ergebnisse des ersten Teils vertiefen und weiterverarbeiten.
Ein kurzer Rückblick auf Teil 1 der Blogserie
Im Ausgangsszenario der Entwicklung eines Multimediasystems haben wir ChatGPT dazu genutzt, uns bei der Identifikation der relevanten DSGVO-Artikel zu unterstützen. Dieser erste Schritt war vielversprechend und bot eine umfassende Übersicht über verschiedene Artikel und Prinzipien zum Datenschutz. Mit diesen Informationen haben wir eine solide Datengrundlage geschaffen, die nun als Ausgangspunkt für weitere Arbeiten dient.
Ein wichtiges Fazit aus den ersten Schritten ist, dass die KI zwar nicht in der Lage ist, die Rolle des Requirements Engineers zu ersetzen, jedoch als wertvolles Instrument dienen kann, um die Arbeit des Requirements Engineers zu unterstützen. Eine Zusammenarbeit mit Rechtsanwälten und eine individuelle Anpassung an den Projektkontext sind entscheidend für eine erfolgreiche Entwicklung.
Artikel verpasst? Hier geht es zu Teil 1!
Zweiter Schritt : Analyse und Kategorisierung
Im nächsten Schritt planen wir, die von der KI im vorherigen Schritt identifizierten DSGVO-Artikel einer eingehenden inhaltlichen Analyse zu unterziehen. Dabei werden die einzelnen Artikel mit verschiedenen Attributen versehen oder bestimmten Kategorien zugeordnet. Diese Attribuierung und Kategorisierung dienen dazu, die spätere Integration in die Datenbank eines RM-Tools zu erleichtern. Durch diese strukturierte Herangehensweise wollen wir die Arbeit mit dem RM-Tool optimieren und eine effiziente Verwaltung der Informationen gewährleisten. Um die Artikel verständlich zu kennzeichnen, werden sie exemplarisch mit Stichwörtern und kurzen inhaltlichen Beschreibungen versehen. Zusätzlich planen wir, die identifizierten DSGVO-Artikel mit Bezug zur rechtlichen Verbindlichkeit der Anforderungen zu kategorisieren, um ihre Dringlichkeit und Wichtigkeit hervorzuheben. Diese rechtliche Priorisierungsschicht kann dazu beitragen, eine gezieltere Umsetzung in der Entwicklungsphase zu erleichtern.
In unserem Prompt fordern wir die KI daher auf, die im ersten Schritt identifizierten DSGVO-Artikel mit Attributen und Stichwörtern zu versehen. Dabei geben wir vor, dass die gewählten Attribute und Stichwörter so gestaltet sein sollen, dass sie durch eine einfache Datenbankabfrage schnell gefunden werden können. Wir geben testweise zwei Vorgaben zur Kategorisierung:
- Die KI soll die einzelnen Artikel inhaltlich analysieren und dabei für jede einzelne Vorschrift bewerten, ob es sich um eine „Muss-“, „Kann-“ oder „Soll-“ Vorschrift handelt.
- Die KI soll die einzelnen Artikel mit Stichwörtern versehen.
Unser Prompt lautet folgendermaßen:„Versehe die eben genannten DSGVO- Artikel mit Attributen und Stichwörtern, damit sie leicht in einer Datenbank gefunden werden können. Eines der Attribute muss sein, ob es sich bei der Norm um eine „muss“, „soll“ oder „kann“ Vorschrift handelt.“
Anwort von ChatGPT:
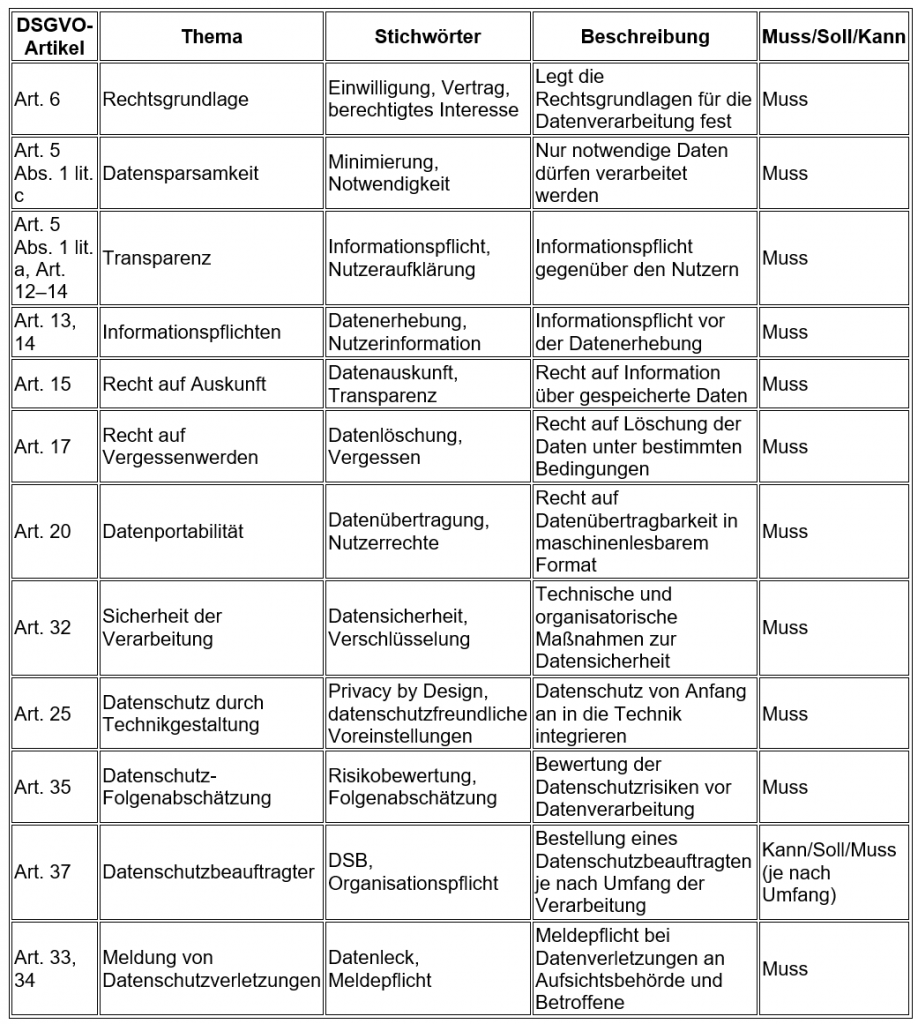
Bitte beachten Sie, dass dies eine vereinfachte Darstellung ist und im Kontext der spezifischen Anforderungen Ihres Projekts eine vollständige rechtliche Beratung erforderlich ist.“
Wie gut finden wir dieses Ergebnis? Wir finden es gut, dass das Ergebnis von ChatGPT auch ohne explizite Anweisung im Prompt in einer übersichtlichen Tabellenform geliefert wird. Neben den Vorgaben bezüglich der Stichwörter und des „Muss-“, „Soll-“ oder „Kann“-Attributs hat sich die KI zusätzlich dazu entschieden, die Artikel nach „Thema“ zu differenzieren und eine kurze inhaltliche Beschreibung der Artikel hinzuzufügen.
Es ist positiv anzumerken, dass die KI korrekt erkannt hat, dass fast sämtliche im ersten Schritt identifizierten DSGVO-Artikel als „Muss“-Vorschriften einzustufen sind. Dies bedeutet eine klare und zwingende Verpflichtung, die einzelnen Vorgaben zu erfüllen. Die Ausnahme bildet Art. 37 DSGVO, in dem die Notwendigkeit eines Datenschutzbeauftragten geregelt wird. Hier bestehen rechtliche Unterschiede, die für den Requirements Engineer von Bedeutung sind. Es empfiehlt sich, insbesondere in Bezug auf Art. 37 DSGVO genauer hinzuschauen, um die Unterschiede in der rechtlichen Bewertung herauszuarbeiten. Der Requirements Engineer könnte hier weiterhin die Unterstützung der KI nutzen, um die rechtlichen Feinheiten des Artikels zu analysieren, oder alternativ einen rechtlichen Fachexperten gezielt zu konsultieren.
Außerdem hätten wir uns gewünscht, dass die KI bei der Kategorisierung nach Stichwörtern zumindest einen einheitlichen Begriff wie z.B. „Datenschutz“ erkennen würde. Dadurch könnten die für das Projekt relevanten DSGVO-Artikel innerhalb einer mit zahlreichen relevanten Gesetzestexten gefüllten Datenbank schnell identifiziert werden. Dies ließe sich möglicherweise durch eine Anpassung des Prompts erreichen.
Zwischenfazit: Auch in diesem Schritt wird die Bedeutung einer menschlichen Komponente in Form des Requirements Engineers deutlich. Je nach Kontext des jeweiligen Entwicklungsprojekts können sich die für die Systementwicklung benötigten Informationen unterscheiden. Es liegt in der Verantwortung des Requirements Engineers, in enger Zusammenarbeit mit Stakeholdern, Entwicklern und rechtlichen Fachexperten die Anforderungen an das zu entwickelnde System zu ermitteln. Insbesondere im Kontext rechtlicher Rahmenbedingungen ist eine umfassende Datensammlung von entscheidender Bedeutung.
Sobald der Requirements Engineer also weiß, welche Informationen zusätzlich zu den identifizierten Artikeln benötigt werden, kann er unterstützt durch die KI diese Datenbasis aufbauen. Diese Datenbasis dient dem allgemeinen Verständnis der rechtlichen Normen und kann dann weiter genutzt werden, um daraus Anforderungen an das zu entwickelnde System abzuleiten.
Ausblick auf den nächsten Teil der Blogserie
Ein weiterer wichtiger Schritt ist nun geschafft. Die KI hat erfolgreich die im ersten Schritt identifizierten DSGVO-Artikel mit zusätzlichen Informationen angereichert. Im kommenden Teil dieser Serie stehen wir vor der Herausforderung, mithilfe der bisherigen Datenbasis konkrete Anforderungen für unser Multimediasystem abzuleiten.
Wir laden Sie ein, weiterhin gespannt dabei zu bleiben!
Bis dahin, IHRE SOPHISTen