
Im letzten Artikel aus unserer Blog-Serie zum Thema Künstliche Intelligenz und Requirements Engineering haben wir Ihnen NLP und NLU erklärt. In diesem Artikel stellen wir Ihnen einige Tools vor, die NLP nutzen um Texte in ihre Bestandteile zu zerlegen.
Um die Funktionalitäten der Tools zu verstehen, muss man die grundlegenden Fähigkeiten, welche diese Tools bereitstellen können, erklären:

Stemming
Beim Stemming werden Wörter auf ihre Grund- oder Stammform reduziert, was normalerweise durch Entfernen von Anhängen wie -en, -t und -end erfolgt. Zum Beispiel wäre der Stamm von „laufen“ „lauf“. Stemming wird verwendet, um Textdaten zu normalisieren und die Dimensionalität des Merkmalraums zu reduzieren.
Lemmatisierung
Die Lemmatisierung ähnelt dem Stemming, aber anstatt nur Affixe zu entfernen, ordnet es Wörter ihrer Grundform zu, die als Lemma bezeichnet wird. Dieser Prozess berücksichtigt den Kontext des Wortes und seine Wortart. Zum Beispiel ist das Lemma von „läuft“ „laufen“ und das Lemma von „lief“ ist „lauf“. Die Lemmatisierung hilft, die Bedeutung der Wörter in Textdaten zu bewahren.
Tagging von Wortarten (TvW)
Beim TvW wird jedem Wort in einem Satz ein grammatikalischer Tag zugewiesen, das auf seiner Wortart basiert, z. B. Substantiv, Verb, Adjektiv, Adverb usw.
TvW hilft bei der Identifizierung der Struktur und Bedeutung eines Satzes und wird in vielen NLP-Aufgaben wie der Erkennung benannter Entitäten und der Stimmungsanalyse verwendet.
Entitäten Erkennung (EE)
EE ist der Prozess der Identifizierung und Kategorisierung benannter Entitäten in Textdaten, wie z. B. Personen, Organisationen, Orte, Daten und Zeiten. EE wird in der Regel mithilfe von maschinellen Lernalgorithmen durchgeführt, die mit annotierten Datensätzen trainiert wurden. EE wird in vielen Anwendungen verwendet, z. B. bei der Informationsextraktion, der Beantwortung von Fragen und der Textzusammenfassung.
Tokenisierung
Ein Beispiel für die Tokenisierung wäre die Aufteilung eines Satzes in seine einzelnen Wörter, wobei jedes Wort ein Token ist. So würde der Satz „Ich gehe spazieren“ in die Tokens „Ich“, „gehe“ und „spazieren“ aufgeteilt werden.
Welche Tools haben sich bereits auf dem Markt etabliert?
Die im folgenden aufgeführten Tools stellen teilweise diese Funktionen und noch weitere zur Verfügung. Sie repräsentieren nur einen kleinen Teil der NLP Tools, sind aber in dem was sie tun sehr erfolgreich.
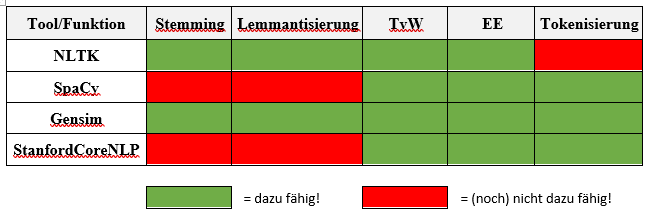
NLTK (Natural Language Toolkit)
NLTK ist eine beliebte Open-Source-Bibliothek in Python für NLP. Es bietet die oben beschriebenen Funktionalitäten. Es enthält auch eine umfangreiche Sammlung von Korpora, bei denen es sich um große und strukturierte Textsammlungen handelt, die für die Sprachforschung verwendet werden.
SpaCy
SpaCy ist eine weitere beliebte NLP-Bibliothek in Python, die für die industrietaugliche Verarbeitung natürlicher Sprache entwickelt wurde. Es ist schnell und effizient und umfasst die oben markierten Funktionen. SpaCy bietet auch vortrainierte Modelle für verschiedene Sprachen, was den Einstieg erleichtert.
Gensim
Gensim ist eine Python-Bibliothek für Themenmodellierung, Dokumentähnlichkeitsanalyse und Text-Clustering. Es verwendet unbeaufsichtigte Algorithmen für maschinelles Lernen, um die zugrunde liegenden Themen in einer Reihe von Dokumenten zu identifizieren, was es zu einem nützlichen Werkzeug für die Analyse großer Mengen von Textdaten macht.
Stanford CoreNLP
Stanford CoreNLP ist eine Suite von NLP-Tools, die von der Stanford NLP Group entwickelt wurde. Es umfasst Tools für Tokenisierung, Tagging von Wortarten, Entitäten Erkennung, Stimmungsanalyse und Analyse von Abhängigkeiten. Es bietet auch voreingestellte Modelle für verschiedene Sprachen, was den Einstieg erleichtert.
Diese vier NLP-Tools bieten ein breites Spektrum an Funktionalitäten zur Verarbeitung und Analyse menschlicher Sprache. Sie können für verschiedene Anwendungen, wie Textklassifikation, Stimmungsanalyse und Themenmodellierung verwendet werden, was sie zu unverzichtbaren Werkzeugen für jeden macht, der mit Daten in natürlicher Sprache arbeitet
Im nächsten Blogartikel dieser Reihe welcher voraussichtlich am 25.04.2023 erscheinen wird, beschäftige ich mich mit den Anwendungsfeldern von KIs im Requirements Engineering.
Seien Sie gespannt!